A small pixel-art avatar that lip-syncs to generated speech. It materializes, idles, glances around, blinks, and pronounces the phonemes of a synthesized voice line. A version of it runs on the homepage of johnsylvain.me.
The avatar is a single sprite sheet driven by audio. There is no rigging or animation engine — just 27 frames, swapped in time with the sound.
Interactive demo
The avatar in the demo above is reading this script:
Welcome to Artifact Lab. This is my private design studio for building physical systems that combine software, electronics, and hardware. I use it to design and prototype devices meant to exist in the real world. Most projects involve embedded computers, custom enclosures, media workflows, and repurposed technology. The focus is on function, clarity, and process, rather than polish.
And yes, the voice you are hearing right now is generated, and the face is a dithered pixel version of mine. If you want to know how that works, keep reading.
The sprite sheet
The sprite sheet has 27 frames:
- 13 frames for a materialization animation that plays on load
- 11 frames of mouth shapes for vowel and consonant pronunciations (visemes)
- 3 frames for idle states: looking left, looking right, and blinking
Everything the avatar does is a sequence over those cells.
Generating the visemes
The viseme set comes from this viseme reference, reduced to the 11 mouth shapes needed for English. Each shape is described as a prompt and applied to a single portrait photo using gpt-image-2 in the OpenAI console. Generating from the same source image keeps the face consistent across frames; drift in shape or lighting breaks the effect.
The output images are assembled into a sheet and run through the Floyd-Steinberg dithering algorithm to get the pixel-art look.
Mapping phonemes to visemes
Audio is generated with Piper, a lightweight Python text-to-speech library. Piper exposes phoneme data alongside the audio: the phonetic units being produced, with timing.
Each Piper phoneme is mapped to a viseme sprite, and the sheet is stepped through in time with playback. The mouth tracks the actual sounds, not the shape of the waveform.
Timing and coverage
Two issues showed up once the mapping was running.
The first was flicker. Swapping sprites the moment each phoneme starts produces rapid alternations that read as noise. A metric counts rapid sprite alternations so minimum-hold durations can be tuned until the motion looks like continuous speech.
The second was coverage. Piper emits about 40 phonemes; the sheet only has 11 visemes. Without a fallback, unmapped phonemes drop to a default frame and the mouth stops moving. A second metric logs unmapped phonemes during playback. Running a few representative scripts through it produced the data used to build a fallback table mapping each missing phoneme to its nearest visual match.
The editor
A small web app runs the whole pipeline. It takes a phrase, generates the speech, runs the phoneme-to-viseme mapping, and renders the result live next to the controls.
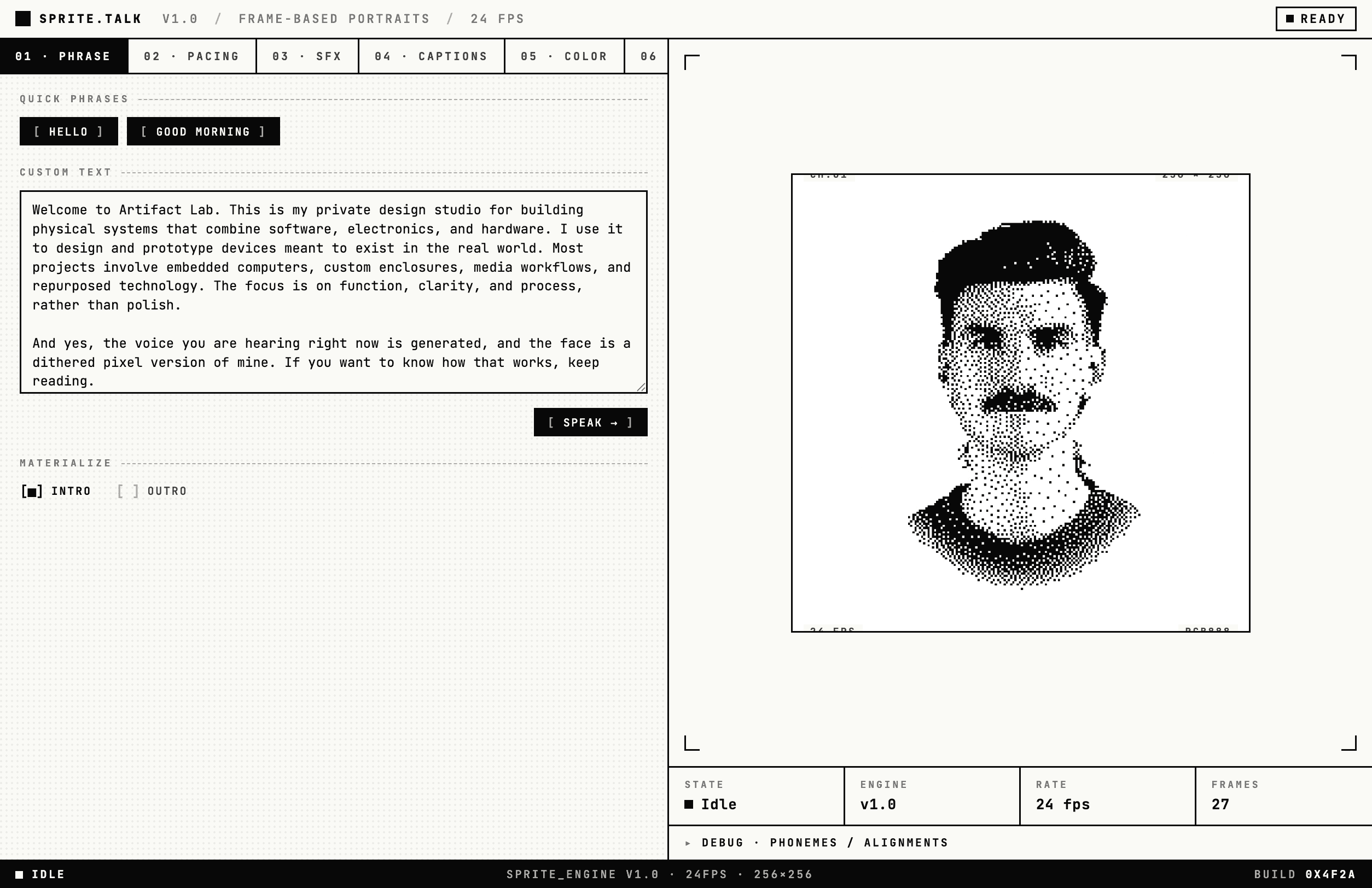
The right panel previews the avatar as it appears when embedded. The left panel exposes the parts of the pipeline worth tuning: pacing, sound effects, captions, and the materialize intro and outro. The flicker and unmapped-phoneme metrics live behind the debug links at the bottom of the window.